Writeup - Everlasting_Message (Codegate Quals 2024)
Codegate Quals 2024 - Everlasting_Message
Description
1 | This binary won't stop sending messages. It seems to be trying to tell us something important... |
Writeup
Introduction
This was an interesting rev challenge that was hard enough to stretch me but easy enough for me to still solve within the 24 hour timeframe. I got the second solve and it took me about 5 hours to finish. You are given 2 files:
- A 64-bit x86 stripped executable
messageswritten in C - A 200 MB file of binary data called
flag_enc(too big to include here)
Based on the name of the binary data and after initial inspection of the main() function in messages, the intended usage is ./messages input_file output_file, and it was run with flag as the input and flag_enc as the output. Therefore, if we can determine the encrypting/encoding mechanism implemented in the binary, we can reverse that process and apply it to flag_enc to recover the initial flag file. Also, since flag_enc is ~200 MB, unless this encoding mechanism is horribly inefficient, we can assume the original flag file is about the same size and is probably an actual file type (like PNG or something) instead of a normal flag.txt.
My goal for this writeup is to clearly explain the steps I went through to understand the binary and implement the solution, perhaps even a little too in depth.
Concepts/Functions to Understand
The first thing I always do when reversing a binary is understand any C functions being used that I do not know personally or very well. For writeup’s sake, I’m going to define and explain all the important C functions and concepts used in this binary.
File Opening & Reading
int open(const char *pathname, int flags, mode_t mode)- When opening a file, the
open()function is used. In C, this code looks likeopen('file.txt', O_CREAT | O_RDWR, 0777). Notice how the flags are initialized as constants being ORed together; somewhere in glibc source code, these constants are set to a number with only 1 bit set, so if you OR 2 of these constants together, you get a number with 2 bits set. - For example,
O_WRONLYis set to0b1andO_TRUNCis set to0b1000000000, thereforeO_WRONLY | O_TRUNCbecomes0b1000000001, or 513. - When code is compiled, those constant labels are lost and simply replaced with 513. When reverse engineering, you need to figure out what bits are set and which constants those correspond to in order to determine the original flags being passed (ChatGPT is pretty good at this).
- When the
O_CREATflag is passed in and a file is being created, the third parametermodeis required (not necessary otherwise);modespecifies the file permissions on the created file in octal. So if you wanted to make the permissions 777, you’d pass in0777(note leading 0 for octal) which is511or0x1ff - The return value is a file descriptor (positive integer) that corresponds to that file.
- When opening a file, the
ssize_t read(int fd, void buf[.count], size_t count)- To read data from an open file, the
read()function is used. The first argument is the file descriptor from theopen()call, then a pointer to an array where the read contents are stored, then the maximum number of bytes to be read from the file. Note that consecutive calls toread()with the same fd will pick up where the previous call left off, meaning you don’t read the samecountbytes from the fd each time.
- To read data from an open file, the
Message Queues
In an Operating System, messages queues are used to facilitate Inter-Process Communication (IPC) so different processes can talk and share data asynchronously. They use a sub/pub design where you can publish messages to a message queue and receive messages from a message queue. Message queues are created with msgget(), messages are sent using msgsnd(), messages are received using msgrcv(), and message queue commands are sent using msgctl().
int msgget(key_t key, int msgflg)(ref)- Just like
open(), constants are used for thekeyandmsgflgarguments which can be found in/usr/include/bits/ipc.h. - If the key is
IPC_PRIVATE(or0), then a new message queue is created with the file permissions set bymsgflgin octal. - The response is an integer identifying the message queue, much like a file descriptor for opened files. We’ll use msqid for shorthand.
- Just like
int msgsnd(int msqid, const void msgp[.msgsz], size_t msgsz, int msgflg);(ref)- The first argument is the msqid, the second is a pointer to a
msgbufstruct containing message data, the third argument contains the size of one of themsgbufstructs inmsgp, and the last argument specifies flags. - When calling this function, it will wait until a message comes from another process before continuing on.
- The first argument is the msqid, the second is a pointer to a
ssize_t msgrcv(int msqid, void msgp[.msgsz], size_t msgsz, long msgtyp, int msgflg);(ref)- Same as
msgsndexcept it sends the message to the message queue and continues.
- Same as
int msgctl(int msqid, int cmd, struct msqid_ds *buf);(ref)- The
cmdargument uses constants also which determine what the OS should do with the message queue in question. Note that thecmdIPC_RMIDis0and means to destroy/remove the message queue.
- The
The second argument of msgsnd and msgrcv is a msgbuf struct which looks like this (ref):
1 | struct msgbuf { |
The mtype field is kind of like an identifier for the data going across message queues so you can tag it and say “this message is meant for this purpose” to deconflict multiple processes in the same queue looking for different types of messages.
Note that the size of the mtext field is variable depending on the needs of the program. For this challenge, this size is 0x10 bytes. I created this struct in Ghidra using the Data Type Manager window so I could set stack variables equal to this datatype:
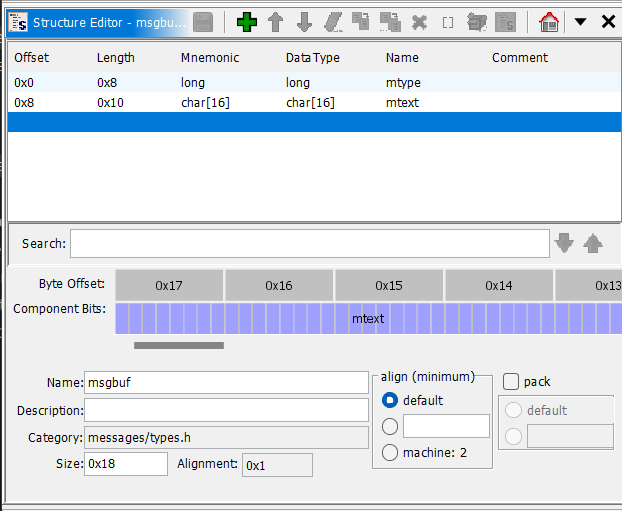
Process Threads
int pthread_create(pthread_t *restrict thread, const pthread_attr_t *restrict attr, void *(*start_routine)(void *), void *restrict arg);- To create a new thread in the same process, you can use the
pthread_create()function. The first argument specifies where a pointer to the returnedpthread_tobject should be stored, the second argument specifies attributes about the created thread, the third argument is a pointer to a function that the thread should run on startup, and the fourth argument is a pointer to the singular argument function ran on startup. - Note that this only allows for a single argument to be passed to the function, so if the function requires multiple arguments a workaround like a single struct with all the arguments must be used instead.
- To create a new thread in the same process, you can use the
In our case, there are multiple arguments being passed to the thread function with a custom struct that looks like this (dubbed arg_struct):
1 | struct arg_struct { |
I also created this struct in Ghidra using the Data Type Manager:
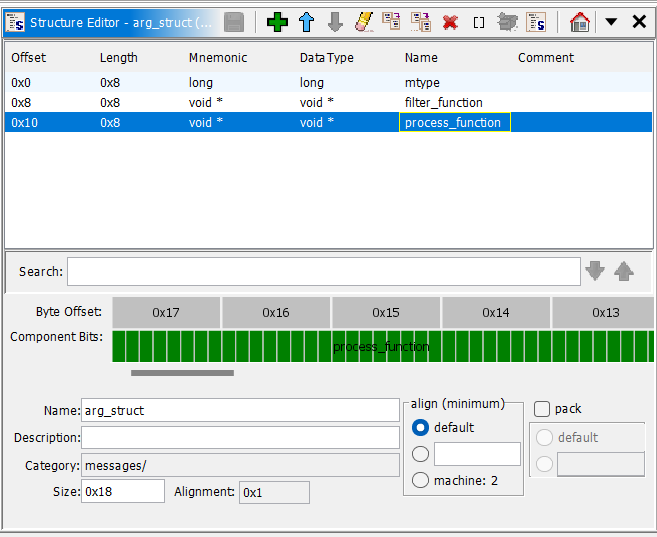
main() Cleanup
After creating the custom structs, cleaning up data types and variable names, and adding comments, I was able to decompile the main() function into much nicer code (see what it looked like in Ghidra before here):
1 | /* STRUCTS */ |
Here’s the written rundown of what main() does:
- First argument is file with input, second argument is file for output
- Create 2 message queues, one to send data to threads and one to receive responses from the threads
- Create 4 threads for processing data from input file
- Read the content from the input file (padding to a multiple of 10 bytes) and split into chunks of 10 bytes
- Send the 10-byte chunk to each of the threads using a message queue
- Receive a response from each of the threads using a message queue and write it to the output file
So it seems the actual encoding/processing functionality takes place in the threads (for obfuscation purposes? efficiency sake?) and main() is just the taskmanager. Time to analyze the thread functions!
thread_run() Cleanup
I cleaned up the thread_run function which looks like this:
1 | /* STRUCTS */ |
Here’s the written rundown of what thread_run() does:
- Get a 10-byte chunk from
main(), pull out 5 nibbles, and run those nibbles through processing_function (3rd field of function argument) - Flip 0-2 random bits of the 5-byte output
- Send the 5-byte output back to
main()to be written to the output file
There’s a couple important things to note going on here. First, this conversion process is lossy since random bits are flipped. However, the processing functions take in 5 nibbles and gives out 5 bytes (much larger keyspace). This means that even with lossy data, the chance of collisions (two nibbles each with 0-2 random flipped bits producing the same 5-byte output) is very small. A bit of brute force, luck, and tolerance for corrupted data should get us through that.
Second, each thread has a different filtering_function and processing_function. The first thread takes the first 5 nibbles, the second thread takes the next 5 nibbles, etc., so threads don’t process the same data ever. Also, the processing functions do a lot of binary arithmetic but are not dependent on any outside factors or previous inputs so they are deterministic. Since there are only 16 ** 5 = 1_048_576 input possibilities, that means we can map all possible inputs to the output for each function. Note that the processing functions are like a thousand binary arithmetic operations and is not meant to be statically reversed lol.
Approach to Solve
Now that we’ve reversed the program and understand what it does, a solution is in sight:
- First, we need to script GDB to run each of the processing functions with all possible inputs and retrieve the outputs (this way we can figure out what 5-nibble input produced the 5-byte output we have).
- Second, we need to read in
flag_encand split it into 20-byte chunks. For each chunk, we need to split that into 4x 5-byte sections (the 5-byte output from each thread) and generate all variations of that 5-byte segment with 0-2 random bit flips. - Third, we look through our map from Step 1 to see which of the 5-byte variations actually map to a 5-nibble input (there should only be 1 most of the time).
- Fourth, take the 5-nibble input we get from Step 3 and write it to a file to recover the original file.
Since this was a lot of computations to do, I decided to parallelize the work by splitting flag_enc into 8 files and running my solve script in 8 different terminals. This is scripted in split.py (I did last 20 bytes by hand):
1 | def split(input_file): |
I wrote a Python script to run the ./messages binary in GDB and call each of the four processing functions using their non-ASLR addresses with all possible inputs in calculate.py by running gdb -q -x calculate.py:
1 | ### MAP INPUTS TO OUTPUTS ### |
That script gave me 4 JSON files that I could import into my final solve script. I then wrote a script that reads in those JSON files, formats the data as a dictionary with key:value pairs as output:input pairs, and does steps 2-4 using some probably overly complicated Python shenanigans. ChatGPT helped write my helper functions. Note that my script was missing something because even with all 0-2 random bit flips on a 5-byte output, sometimes none of them matched to a 5-nibble input. In that case, I just arbitrarily set the input as 0xfffff and hoped the corrupted data wouldn’t be too bad. That resulted in this script:
1 | import sys |
Running across all 8 terminals, it took about 40 minutes to complete. At that point, I just ran cat flag_1 flag_2 flag_3 flag_4 flag_5 flag_6 flag_7 flag_8 > flag.mp4 to get the mp4 file. It was corrupted, but uploading it to an online site to fix it gave me a video that worked!
Flag: codegate2024{fun_fun_coding_theory}